Overview
This section gives a high-level overview of the different steps taken by DeepCASE to perform a contextual analysis of security events and explains how DeepCASE clusters events to reduce the workload of security analysts.

Figure 1: Overview of DeepCASE.
Event sequencing
The first step is to transform events stored in your local format into a format that DeepCASE can handle.
For this step, we use the Preprocessor class, which is able to take events stored in a .csv and .txt format and transform them into DeepCASE sequences.
For the required formats for both the .csv and .txt files, we refer to the Preprocessor reference.
Context Builder
Next, DeepCASE passes the sequences to the ContextBuilder.
When receiving sequences, the ContextBuilder first applies its fit() method to train its neural network.
Once the network is trained, we use the ContextBuilder’s predict() method to get the confidence in each event with its context and attention for all events in the context.
These confidence and attention values can then be passed to the Interpreter together with the events and their context for clustering.
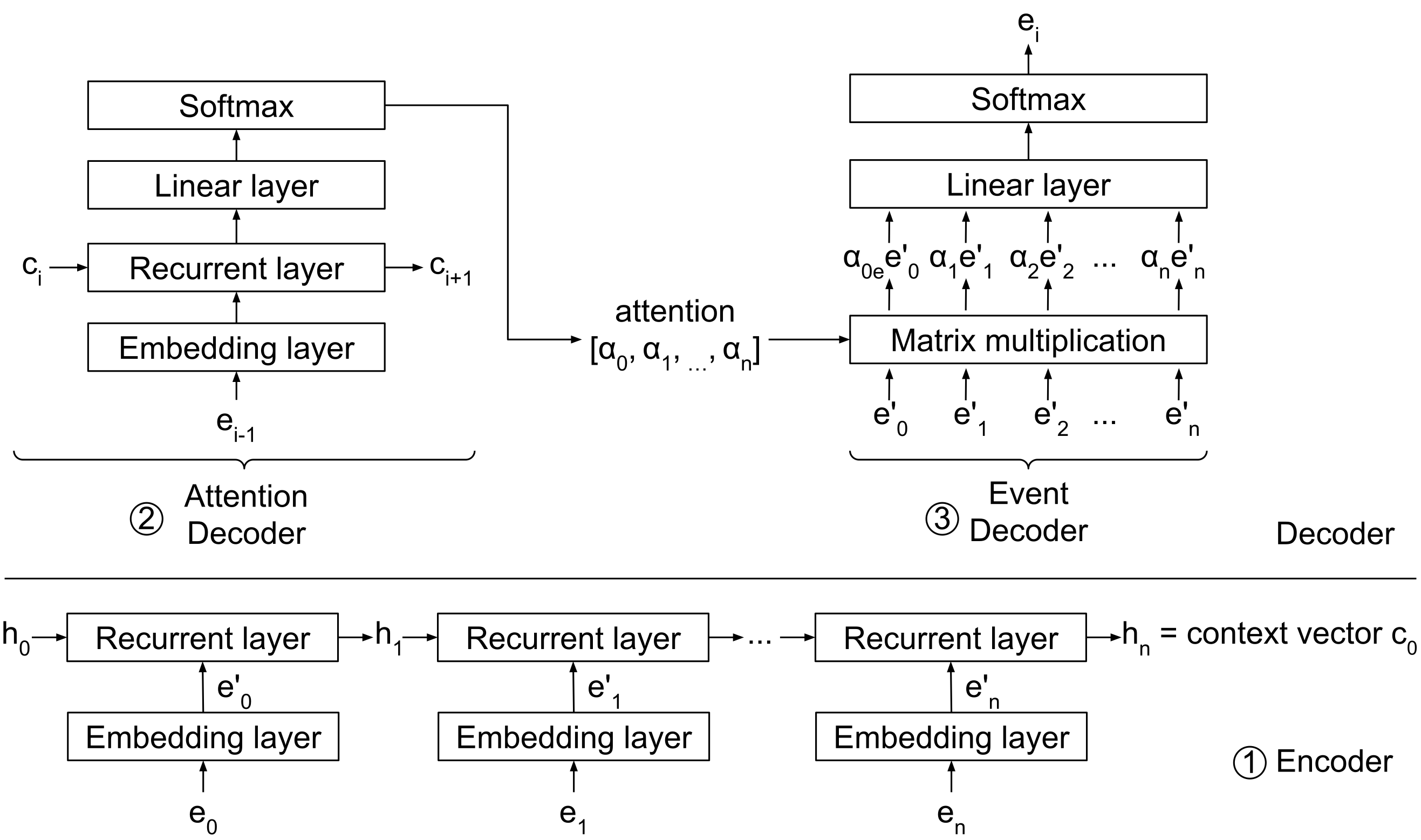
Figure 2: Architecture of DeepCASE’s Context Builder.
Interpreter
The main task of the Interpreter is to take sequences (consisting of context and events) and cluster them.
To this end, the Interpreter invokes the ContextBuilder’s predict() method and applies the attention_query() to obtain a vector representing each sequence.
These vectors are then used for clustering.
Afterwards, clusters can be manually analysed and assigned a score.
After assigning a score to existing clusters, the Interpreter can compares new context and events to existing clusters and assign the scores (semi-)automatically.
For sequences that cannot be assigned automatically, the Interpreter gives an output indicating why a sequence could not be assigned automatically.
Manual Analysis
In manual mode, we use the interpreter.Interpreter.cluster() method to cluster sequences consisting of context and events.
This method returns the cluster corresponding to each input, or -1 if no cluster could be found.
Next, we can manually assign scores using the interpreter.Interpreter.score() function.
This function takes a score for each clustered sequence and assigns it to the corresponding clusters such that these scores can be used for predicting new sequences.
Note
- The
interpreter.Interpreter.score()function requires: that all sequences used to create clusters are assigned a score.
that all sequences in the same cluster are assigned the same score.
If you do not have labels for all clusters or different labels within the same cluster, the interpreter.Interpreter.score_clusters() method prepares scores such that both conditions are satisfied.
Semi-automatic Analysis
In semi-automatic mode, we use the interpreter.Interpreter.predict() method to assign scores to new sequences (context and events) based on known clusters.
It will either assign the score of the given cluster or a score of:
-1, if the ContextBuilder is not confident enough for a prediction.
-2, if theeventwas not in the training dataset.
-3, if the nearest cluster is a larger distance thanepsilonaway from the sequence.